Step by Step from Monolith to Microservices
Introduction: Monolith vs. Microservices #
Many people are talking about microservices these days and argue how you should (almost) always build your backend using a microservice architecture if you don’t want to run into scalability issues. While they certainly have a point regarding the potential of scalability, I don’t think it’s always a smart decision to build your backend as a fleet of microservices per se. In my opinion (which is shared by others too), the decision depends on (among other factors) the team size and the kind of software product you’re building. If you have one backend developer and no fully validated business model (and instead you’re experimenting with and validating your value and growth hypotheses (as you should)), in many cases I think starting with a monolith is the better choice. It will allow you to get started faster, you’ll only have a single code base, much less complexity in deployment and it will allow you to move fast, which is especially important in the beginning (and often considered the main advantage small startups have against big tech companies).
Still, the monolith should obviously be well-architected, respecting common code style maximes like separation of concerns, SRP, ETC (easy to change) and so on. This will minimize technical debt and pave the way for your transition to microservices later on (if needed).
Transitioning to a Microservice Architecture #
Once you have some traction and can affort a bigger engineering team, I think it makes sense to iteratively transition your backend to a microservice architecture, step by step. This means that you could
- build new components (for new features) in an isolated fashion as a separate service whenever possible
- for example: adding smart ML recommendations to the system, encapsulated in a microservice (see case study below)
- refactor out some existing component of the monolith that’s “quite” independent to a separate service when working on it
- for example: packaging the payment processor into a separate service when you need to make some changes to it anyways
- isolating new (types of) databases and data entities in their own service when the need arises
- for example: hiding a new NoSQL database for tracking user behavior behing a microservice
The communication of these new microservices among each other and with the main monolith could be done in different ways. Here are some suggestions:
- synchronous: use internal (REST, GraphQL, …) APIs in your local network (e.g., in your AWS VPC) that your services use
- for example: your payment processor microservice exposes an internal API for processing payments and providing information about past payments
- asynchronous: use tasks queues (e.g., using a managed service like SQS or building your own queue using a Redis database or a RabbitMQ message broker)
- for example: your main monolith puts user interaction data into a task queue that your microservice consumes and stores in a database
By adding separate microservices step by step as your backend evolves, its scalability will improve, more developers will be able to work on different services independently as you grow, and you can make local technical choices in each service without having to compromise because of other services that have other requirements. You can also benefit from writing the different services in different programming languages, choosing the perfect language for each use case.
Case Study: Adding ML Recommendations #
To illustrate this iterative transition from a monolith to a microservice architecture, let’s have a look at the following real-life case study of our recent effort of adding machine-learning driven recommendations to our existing monolith architecture. I’ll first describe the goal of the project and the existing monolith architecture on a high level, and then dive into the details about how we implemented the new service in an isolated fashion. I’ll also discuss tradeoffs for each key decision we made.
Project Description #
In order to provide more value to customers and improve the user experience of our product, we were planning to add user recommendations. We wanted to deploy different recommendation models at the same time and perform A/B-tests among them to guide our development of recommender systems in the right direction. In addition, we wanted to continuously learn from user data to improve our recommendation models.
In order to slowly transition to a microservice architecture, we decided to create a new isolated service that accomplishes these tasks. It manages different recommendation models, conducts A/B-tests among them and evaluates the accuracy of these models (and can show those evaluations in a dashboard). We call it Apollo (after the Greek god of prophecy). Note that the recommendation models it manages could be deployed as standalone microservices too.
The Existing Monolith #
The other parts of our backend are architected as a monolith. This monolith exposes a JSON REST API to our web and mobile client applications. It manages user data, content and payments (among others). Internally, though they currently use one single MySQL database and are all included in one code base, the different services for payments, authentication, content, etc. are written in a decoupled manner.
Detailed System Design #
On a high level, our isolated microservice for generating recommendations within our existing app (Apollo) functions as follows:
- the monolith processes a user’s intent, triggers recommendations to be generated
- the monolith calls Apollo and tells it which user and in which context the recommendations are needed
- Apollo internally selects a recommendation model to use (based on A/B tests)
- Apollo runs this model and receives recommendations
- Apollo sends those recommendations back to the monolith, which provides them to the user
Apollo is a separate microservice with its own database. It can be developed and scaled independently from the monolith, and it only communicates with the monolith using a clearly defined interface.
The high-level system context is illustrated in the following diagram: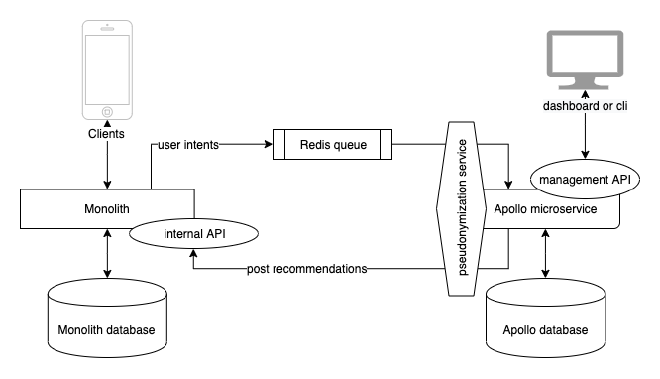
The monolith sends user intents to a Redis queue. Apollo consumes those user intents and first runs them through a pseudonymization service (which we need to apply before the machine learning models to comply with GDPR). Once all user-identifiable information is pseudonymized, Apollo triggers the machine learning model to generate recommendations, which are de-pseudonymized before sending them back to the monolith via an internal HTTP API it exposes. Both the monolith and Apollo have their own databases. Apollo additionally exposes a management API to a dashboard or CLI (to manage A/B-tests, models and evaluations).
Communication #
Monolith to Microservice #
For step 2, when the monolith triggers Apollo to generate recommendations, we use a Redis FIFO queue. More specifically, we use the Bull framework to produce and consume tasks, in the monolith and Apollo. The monolith enqueues “user intent” tasks, which are stored in Redis until they are consumed by Apollo.
Tradeoffs We could have exposed an internal REST API from Apollo to the monolith instead of the Redis queue. In this scenario, the monolith would do an HTTP request to Apollo to ask for (or trigger) new recommendations. However, this would require us to handle Apollo downtime manually (and retry requests after some timeout). By using the Redis queue, we get a buffering behavior for free – if Apollo happens to be down, all tasks are just stored in the queue and are ready to be consumed once Apollo comes back online (e.g., during deployments or maintenance). In addition, we get many additional features for free by using a Bull Redis queue: retries, priority, atomicity (not generate the same recommendations twice), etc.
Microservice to Monolith #
For step 5, when Apollo sends the recommendations it has generated back to the monolith, we use an internal API instead. Apollo sends an HTTP POST request to the main monolith and includes the recommendations in the request body.
Tradeoffs We could have used a queue again. However, for this scenario, the burden of setting up a separate queue outweights the benefits. If the monolith happens to be down, we clearly have a system failure, so the recommendations not being delivered is the least of our problems. So we don’t necessarily need to handle failures in that case. However, if we run into issues with this HTTP API approach, we can still transition to using another mechanism for delivering the recommendations.
Pseudonymization Service #
Before Apollo triggers the recommendation models, it pseudonymizes any user-identifiable information. The pseudonymization service is included in Apollo’s code base.
Tradeoffs In this case, we only use this pseudonymization service for Apollo, so we included it in its code for now. When the need arises, we can still refactor it out to a separate microservice too (since it’s decoupled in Apollo’s code base, this is not a big undertaking). Seen this way, the concept of migrating from a monolith to a microservice architecture can be understood as a recursive effort too – iteratively splitting up “bigger monoliths” into microservices / “smaller monoliths”.
Database #
Apollo needs to store A/B-test data (which recommendation model to use for which users with which probability) as well as user data (to train the recommendation models). While the A/B test data is probably best served by a relational database, the type of user data it stores is best suited for a NoSQL database. Thus, we decided to use a separate MongoDB database for Apollo.
Tradeoffs We could have used the same MySQL database that the monolith uses, however, this would make the two services more coupled and would hinder their independent scalability (which was a clear goal of the architecture). Thus, Apollo manages its own database.
Feature: Evaluating A/B Tests #
To evaluate the accuracy of different recommendation models, we use A/B tests: for some users, model A is used to generate recommendations, and for other users, model B is used. Once the user has chosen among the recommendations, these choices need to be compared to the generated recommendations and the accuracy then recorded for the model that was used to generate the recommendations.
For this feature, we had to design a process that would allow Apollo to learn about the user’s choices among the recommendations it has generated and then reconstruct the model that was being used in order to record the accuracy and later evaluate the A/B test. Apollo should still be working as a fully isolated microservice.
The following diagram depicts the design we came up with: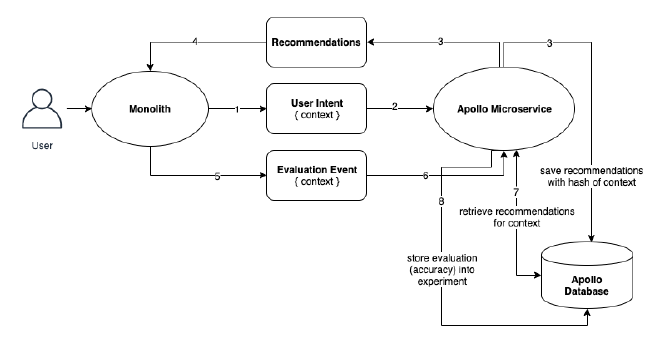
- The user makes an intent, which leads the monolith to send a user intent to Apollo. This event includes the context in which recommendations are needed.
- Apollo receives the intent, selects a model to use based on the currently active A/B test experiments, executes the model and obtains recommendations.
- Apollo sends the recommendations back to the monolith and also stores them along with a hash of the context and the id of the model that was used to the Apollo database.
- The monolith receives the recommendations and delivers them to the user.
- The user’s choice among the recommendations is sent to Apollo. It includes the same context as was delivered in the user intent.
- Apollo takes note of the user’s choice and stores it for later model training.
- Apollo retrieves the recommendations it has generated for the given context of the event (if available in the database), along with the model that was used.
- It compares the recommendations with the user’s choice, calculates the accuracy and updates the model’s average score in the given A/B test.
This way, Apollo stays isolated and all communication between the monolith and Apollo happens through the previously defined channels.
Conclusion #
As I hope the case study has illustrated, it’s possible to iteratively transition from a monolith to a microservice architecture in your backend. Building Apollo (our recommendation service) in this way, instead of including it in the monolith code base, has not cost us a lot more effort. The benefits we can derive from being able to scale the two services independently and being able to work on them independently outweigh the cost of having a separate code base and deployment pipeline to worry about.
We plan to continue with this strategy of iteratively migrating our backend architecture to a fleet of microservices (or, “smaller monoliths”) as we add new features. I hope this post will inspire you to think about how you could perhaps build your next backend feature not as an extension to your monolith but as a separate microservice. If you do, I’d love to hear from you in the comments! Let us know what you’re building and how you’re decoupling it from the monolith.
If you need any help or consulting for your cloud architecture or backend project, feel free to reach out!