How I Cached Map Clusters and Achieved a ~50x Speedup
Introduction: the Problem #
Our mobile app shows markers (points of interest) on a map. Given a zoom level and a longitude/latitude bounding box, an API endpoint returns a list of markers and clusters of markers (called the “map endpoint” in the following).
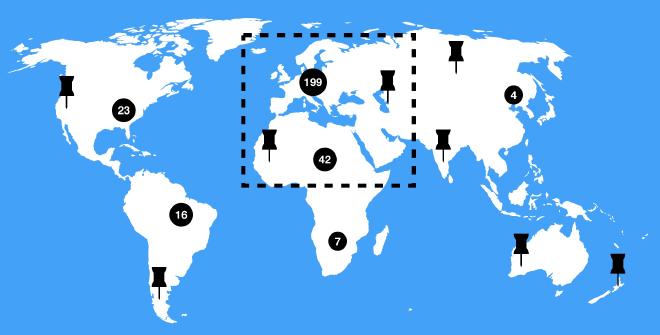
Recently, we scraped the web to find additional points of interest to add to our database of map markers. Before, we had around 400 manually created markers, which didn’t require sophisticated performance optimizations in the map endpoint. However, after some scraping, we had over 10k markers in Germany. Since the map endpoint was not optimized to handle that many markers, its performance dropped significantly: in some zoom levels the API request took approximately 4.3 seconds, which felt very slow to the person using the map. Our goal was to bring down the absolute worst case maximum duration of such a request (even under bad network conditions) to less than 1 second.
How the Map Endpoint Used to Work #
Before the optimizations described in this post, the map endpoint did the following (given a zoom level and a latitude/longitude bounding box):
- query the (relational) database for markers in the latitude/longitude bounding box
- given the zoom level, run a clustering algorithm on the markers
- return a mix of clusters and markers
The first 2 points mainly contributed to the bad performance:
- when the bounding box is large enough (e.g., all of Germany), the result size of about 10k markers (plus some joins) makes the database query very slow (about 1-2s)
- the clustering algorithm adds another ~250ms for clustering 10k markers
For a worst-case query (large bounding box in a dense area), the old endpoint took 4.3 seconds while the new one just takes 73ms, which is a ~58x speedup (that I am very excited about).
Requirements and Goals #
Our use case has some specific characteristics that are important to consider when designing a solution
- we have very frequent reads (multiple per second) but few writes (maybe 5 a day) in the marker database
- when we have a write, it’s enough if the cache is updated within 1 hour (thus, faster cache refreshs are a “non-goal” (nice to have but not important))
From the business case, we derive the following requirements:
- a request must not take more than 500ms
- the system must support 100k markers
- the system must support 10 incoming requests per second
Precise Design of the Solution #
On a high level, the re-architected map endpoint now does the following:
- find clusters and markers from a cache for the given zoom level and in the given bounding box
- enrich markers with data from the database
- return a mix of clusters and markers
The details of how the new endpoint works will be discussed below.
The Cache (Step 1) #
Technology We use Redis, a very fast in-memory database, commonly used as a cache. It supports geospatial indexing using Redis Geospatial, which allows us to store latitude-longitude points (markers) and then query them in a highly optimized way. Under the hood, it uses a sorted set which uses the latitude and longitude as the score of the set using the geohash algorithm (more info can be found here).
Zoom levels Depending on the zoom level and the density of markers in a requested area, the endpoint needs to return a mix of single markers and clusters. The degree of clustering changes based on the zoom level:
- if one zooms in closely (large zoom level), there will mostly be single markers (except in very dense areas maybe)
- if one zooms out far (small zoom level), there will mostly be clusters (except in very light areas with just one marker)
Zoom levels are integer numbers, so we are able to create a separate cache for each zoom level. We use Google Maps in the app, which supports zoom levels from 1 to 20 (in some areas, in others it’s a smaller subrange). Our app further restricsts that to 4-20, so we need to create 17 caches. Each cache contains its zoom level in its name, so we can choose the correct cache for an incoming request.
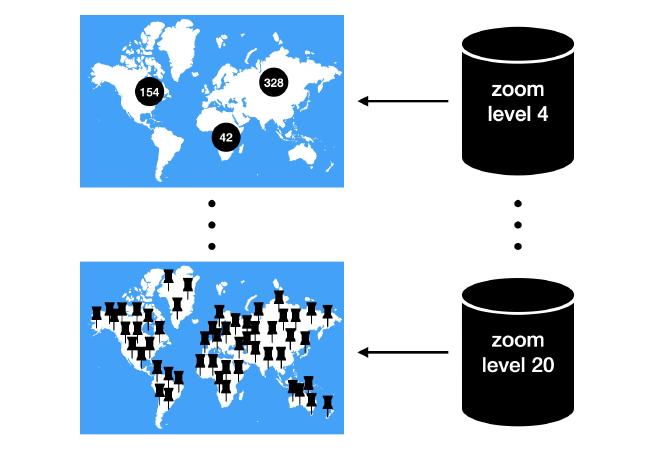
Filling a cache In each cache, we store all markers and clusters from the full globe when clustered with the clustering algorithm which is configured with that cache’s zoom level. Thus, in small zoom levels (zoomed far out), we mostly store clusters in the cache. In large zoom levels (zoomed closely in), we mostly store the markers themselves in the cache.
Cache items We have two different types of cache items: markers and clusters. Since markers require a lot of properties before being displayed in the app, we only store their id and location in the cache item and then fetch the full object from the relational database before sending them to the client. Clusters however just need a number of how many markers they include and their location, so we can store all we need in the cache item. Note that some additional properties for both cluster cache items and marker cache items are needed for the challenges discussed below.
Concretely, as Redis supports only a single string to be stored as the value in a geospatial set (along with the coordinates), we simply format the properties we need into a JSON object and stringify it to get the cache item’s value. Redis allows keys to have a maximum size of 512 MB which is well enough to store the properties described above.
Cache queries We store the cache items for one zoom level in a cache based on their latitude and longitude using the GEOADD Redis command. When a request is coming in, we first convert the given bounding box to a center point and a maxium distance in meters from that center such that the resulting circle includes the full bounding box (see first challenge below). We then use the GEORADIUS command to retrieve candidate clusters and markers.
Considerations #
Invalidating and refreshing the cache As specified in the requirements, we do not need to refresh the cache immediately when there was a write to the markers database. Since not all markers from the database are included on the map, and we have some additional challenges (see section below), it is impractical to trigger a cache refresh each time there has been a change that might affect some markers, since it can happen from many different places and in different circumstances. Thus, we instead periodically refresh the cache once an hour (to guarantee the requirement), and in addition, focus on the most important event that requires a cache refresh. This event is easy to detect in the application and happens at most a few times per day: a new marker is inserted into the database.
To ensure the load on the system refreshing the cache is not too high, we use a queue with a rate limit of 2 tasks per hour. An hourly cron-job triggers a refresh (which is one of 2 refreshs each hour), and when a new marker is inserted, we trigger an additional refresh. In practice, this compromise works very well - it keeps the cache updated after the main events, guarantees an update every hour, and keeps the load on the system reasonably low. In our case, a full cache refresh takes about 8 seconds to complete, during which the system stays fully responsive. Each zoom level’s cache is updated after another, so the time span in which a cache will be empty is very short (approximately 20ms), which is an acceptable value in our use case.
Cache resource needs If we have N markers overall (on the full globe), we need to store at most 17*N cache items, as we have 17 zoom levels. In practice, as the markers are densely clustered in small areas, the total number of cache items in all caches is about 2*N in our case. The smaller the zoom level (i.e., the more far out we are zoomed), the less cache items we store in the cache, as more markers are clustered together. If we assume an average cache value size (the length of the stringified JSON as described above) of 250 characters (which seems to be reasonable in our case) and a string size of 1 Byte per character, we need to store about 2 * N * 250 Bytes of cache values (plus additional Redis-internal data structures for the sorted sets along with their scores). If we have a Redis instance with 1GB of RAM, and we assume that the Redis internals take less than 100 Bytes per cache item, this works out to allow about N <= 1,400,000 markers. Even if the markers are not clustered at all, and we need to store all 17*N cache items, this still allows for N <= 160k cached items, which is much more than we need. According to the Redis FAQ, a Redis instance can handle upto 2^32 > 4 billion keys, so this is not the limiting factor.
Thus, we can conclude that a 1GB Redis instance will suffice until we have significantly (~100x) more markers.
Enriching Markers (Step 2) #
After receiving a list of clusters and markers from the cache, we need to enrich the markers with data from the database before they are delivered to the client. For that, we filter the list of cache items to only include the single markers, map them to their respective ids and then fetch all markers from the database having these ids.
Note that this database query is much faster than the database query in the old implementation. Previously, all markers in the given bounding box were fetched and then clustered. When zooming far out, the number of markers contained in the bounding box is very large, but the number of markers that are delivered to the client after clustering is very little (since most markers are included in a cluster). Thus, by retrieving the clusters and markers from the cache first, and only then fetching the few single markers that are not included in a cluster from the database, we have a much smaller result from the database.
Delivering the Result (Step 3) #
After fetching clusters and markers from the cache, enriching the markers with additional data from the database, we can return the mix of clusters and enriched markers back to the client. Other than the source of where the clusters are coming from, this step does not differ from the previous implementation. However, the time taken to get to this step is much smaller than before.
Challenges #
Apart from the basic solution discussed above, there were some unique challenges I faced in our particular use case. They might not all apply to your case, but you might face some version of them, so I will describe below how I solved them.
Converting the Bounding Box to Center + Radius #
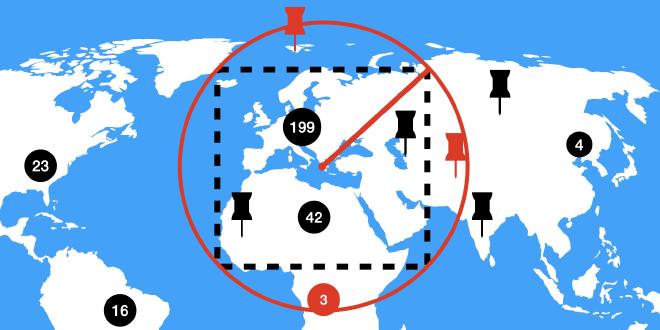
As of this writing, 6.0.10 is the latest stable Redis release version. This version does not support the GEOSEARCH command, which could be used to retrieve cache items in a bounding box. Instead, I use GEORADIUS to query the cache, which expects a center and a radius in meters and then returns all cache items in the resulting circle.
As a workaround, when given the bounding box by the client, I first calculate the maximum distance from the center to the corners of the bounding box (note that the distance in meters from the center to any corner is not necessarily the same). For this, I use the haversine formula that gives me the distance between two points on a sphere, given their coordinates. The maximum distance from the center to the corners is the radius I need to use in the GEORADIUS query such that the result includes all cache items in the bounding box. As a post-processing step, I remove the markers that are not within the bounding box (but within the circle), colored in red in the following illustration:
Aggregated Cluster Availability #
In our business case, each marker needs to be assigned a property that determines if it is available or not. If it’s available, it’s shown in color on the map, otherwise it’s shown in gray. A cluster of markers needs to aggregate this property: a cluster is available if and only if at least one marker in the cluster is available.
Whether or not a marker is available to a user depends on many factors, some of which require additional database queries with multiple joins and it is thus very expensive to compute the availability. This poses several challenges:
- the cache is the same for all users, so we can’t pre-compute the availability and store it in the cache
- if there are many results in a map query, determining the availability will take a long time
Even without the cache, in the previous implementation, we were not able to compute the exact availability of all markers and clusters on a large map bounding box with many markers. The solution we came up with is to use a compromise:
- when filling the cache, we use a very broad
O(1)heuristic for the availability of markers that is user- and time-independent and aggregated in the clusters - at query time, we use the availability as it is coming from the cache for clusters and use a more precise (but still
O(1)) heuristic for single markers that incorporates the user and the current time - if we are zoomed in very close (zoom level >= 15), we do compute the expensive, exact availability for upto 20 markers and otherwise fall back to the user- and time-specific
O(1)heuristic
This way, the accuracy of the availability of clusters and markers increases as we zoom in closer, while maintaining fast request durations.
Map Marker Filters #
Another challenge we had to solve was that the user can set up filters that limit the markers which should be included on the map. This challenge poses different requirements for the two types of map items, clusters and single markers:
- clusters: the number of leaves shown on a cluster item needs to take the filters into account, and if it becomes 0, the cluster should not be included in the response
- single markers: the markers that do not match the filters should not be included in the response
Concretely, the user can specify any subset of about 20 sport forms as a filter on the map. When selecting no filters, markers matching all sport forms will be included in the response. Otherwise, just the markers that match the selected sport forms should be included.
For the single markers, this is easy to solve: when enriching them with additional data from the database, we simply filter out the markers that don’t match any of the requested sport forms. To make the filtering work correctly for clusters however, we need to store additional properties in the cache. In our case, we include a map that maps the sport form to the number of markers in the cluster matching this sport form:

This way, when the user requests map markers with a set of sport forms as the filter, we calculate the number of leaves of each cluster as the sum of markers in that cluster for the given sport forms. If the number of leaves becomes zero, we simply filter out the cluster. In the example cluster above, if the user query’s sport form filter is basketball and soccer, we adjust the number of leaves to be 16 + 3 = 19.
In some cases, this method has a shortcoming, though, which is adressed in the following section.
Clusters of One #
While the clustering algorithm does not output a cluster if it has just one leaf (it just outputs the leaf itself instead), after filtering the clusters for a set of sport forms as described above, it is possible that the number of leaves of a cluster becomes one: if the cluster includes just one marker for a sport form.
In the example cluster above, if the user’s sport form filter is hockey, this cluster would show 1 as its number of leaves.
If this happens, what we would like to do is to not deliver the cluster of one but the single marker represented by the cluster instead. With the current implementation, we don’t know the id of the marker that is the only one for a specific sport form in that cluster, though, so we cannot do that without additional information.
Thus, in each cluster, we need to store the id of any marker that is the only one matching a sport form in that cluster (just for hockey in the example):

This way, we can map any cluster of one to a single marker with the respective id we have stored in the cache item and deliver it as such to the user.
Conclusion #
When you have a database of many geospatial points located densely in a small area, you will most likely need some kind of pre-calculation to ensure fast request durations. The type of technology you use for this purpose depends on the business requirements. Important characteristics are read/write frequency and uptime requirements. In our case, using a Redis cache was the right approach, and it allowed us to achieve extremely fast map requests. Our solution will also allow us to scale to 10x the markers we have now easily.
If you have additional constraints or features that you need to support (like the challenges described above), there is some additional work required to make them work in a cached environment, but with more data being stored in the cache, I believe most of them can be realized.
Do you have any requirements that you cannot solve using any of the approaches above? I am very interested to hear them and how you solved them in the end (if you did), so let me know in a comment below! If you need any help or consulting for your cloud architecture or backend project, feel free to reach out!