How AWS Lambda reuses containers (and how it affects you)
Introduction: A weird Bug with a Lambda #
We have an AWS Lambda set up that is triggered each time a video is uploaded to an S3 bucket. Its task is to download the video, extract some frames from it and then generate a gif out of these frames as a preview of the video. The gif is then uploaded to S3 and used as a thumbnail by the clients.
As we uploaded many videos for testing a new feature, we noticed a weird bug: sometimes, the frames shown in the gif seemed to include frames from another video (i.e., it included frames that were clearly not part of the video for which the thumbnail gif was created).
Uncovering the Reason for the Bug #
I did some research and found out that AWS Lambda invocations are actually not guaranteed to be independent (which I previously assumed was the case).
It’s possible that a container is reused, which causes the /tmp folder to be shared between invocations.
The thumbnail gif generator lambda was using this folder to store the frames of a video before merging them together. It stored them in one folder and then read all files from that folder to merge them together into a gif.
It also did not delete the frames after it was done, since I thought that invocations were independent anyways, so there was no good reason to clean up the files afterwards. Thus, when the container was reused, it used not only the frames of the video it was executed for, but the frames of the previous video processed in the same container as well.
The Theory: AWS Lambda Containers #
AWS Lambda is a serverless service that allows you to execute code without running your own servers. The process of when your lambda is invoked is illustrated below (adjusted from this AWS re:Invent talk):

First, your code is downloaded (e.g., from S3). Then, a new container with the resources you define in the Lambda console is started and the chosen runtime (e.g., Python or Node.js) is bootstrapped. Finally, your code is started.
The first three steps can take quite some time, which is the difference between a “cold start” and a “warm start”. A “cold start” is when no such container is provisioned and the invocation of your lambda needs to go through all four steps. A “warm start” is when a container is already provisioned (has gone through the first three steps) and is ready to start your code.
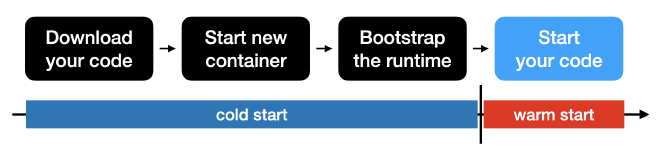
The difference of a “warm start” code execution and a “cold start” code execution can be quite substantial - I found one example of the cold start taking over 1 second while the warm start took just 18ms (which means that the first three steps accounted for more than 98% of the total execution time in this simple case) (source).
Container Reuse #
Due to this large overhead of starting a new container, AWS Lambda attempts to re-use already provisioned containers, i.e., saving you the first three steps. This happens when the code of your lambda has not changed (i.e., you have not made a new deployment) and it’s not been too long since the last invocation (AWS specifies no explicit time frame, source). You can artifically increase the likelihood of a container being reused by increasing the timeout of your lambda.
One caveat that sits at the root of the bug mentioned in the beginning of the post is that the /tmp folder of the lambda container is not cleared upon reuse.
Thus, any files that you deposit there in the first invocation are still there in subsequent invocations. If your lambda executes code similar to mine, this is important to keep in mind.
Taking Advantage of Warm Starts #
Container reuse is not just something that can cause bugs when you don’t account for it in your function’s code. It’s also something that can make your lambdas significantly faster if you exploit it. One way to do so is to define handles to other services such as database or S3 connections in a global variable, rather than re-creating it in the handler of your lambda on each new request. This way, if the container is re-used, so is your handle and the overhead of re-connecting to your database or to S3 is avoided in future invocations.
In experiments (source), this can result in a 3x speedup of the average lambda execution time. The aforementioned article contains some additional details of how you might exploit the container reuse mechanism of AWS lambda.
Conclusion: Resolving the Bug #
To recap, the problem of our thumbnail gif generator lambda was that it stored the frames of the gif in the same folder in /tmp each time and did not clear them in the end.
A trivial solution would be to just delete the folder after the gif has been created and uploaded to S3. However, if this deletion call somehow fails or is avoided, it would result in the same bug again.
Thus, in addition to cleaning up any temporary files after each lambda invocation, I made sure each invocation first generates a random string and then only works in a subdirectory of /tmp called by that random name. This way I could be confident that no two invocations ever shared a folder (with very high probability).
Important is that the random directory name is generated in the handler locally and not stored in some global variable (as the S3 connection might be), otherwise it would be shared by subsequent invocations again.
To conclude, the fact that AWS Lambda reuses containers can speed up your lambdas considerably, even more so if you take advantage it by maintaining shared handles in a global state. However, if you are not aware that this might happen and files might be shared between two invocations, it can cause bugs as well. Thus, it’s important to keep this fact in mind when writing your lambda code.
If you need any help or consulting for your cloud architecture or backend project, feel free to reach out!